Introduction
The Solid project [1] aims to create a decentralized personal data ecosystem based on open standards. Within this ecosystem, each user retains control over their data. Users expose their data through a collection of HTTP documents linked together by Linked Data Platform (LDP) [2], forming what is known as a Solid pod. When querying the data in a solid pod, data consumers, like developers and data analysts, are faced with the access path data-dependency [3]. This means they must know which RDF-resources are exposed through which interfaces at what web-address. For example, social media posts could be exposed in a single document at ‘https://example.org/posts’, but it would be equally valid to expose a collection of documents each grouping the posts of a single day exposed at ‘https://example.org/posts/{creation-date}’. As such, clients that want to access, create or modify data need to explicitly know where to look for the data they need.
To resolve the access path data-dependency, consumers could try to discover all resources exposed by traversing links [4]. However, this method does not scale well as the number of resources increases. To mitigate this, mechanisms can be used to describe the relation between RDF-resources and HTTP-documents that might expose them. The type index [5], shape tree [6], and shape index [7] explicitly define such relationships, reducing the search space to a limited number of HTTP-documents, effectively functioning as indexes[8].
While a lot of research has gone to querying decentralized environments such as Solid, not a lot of research has gone to updating resources in a decentralized environment. Looking at Solid, the existing descriptions do not provide sufficient information to determine where to create or update resources, because a created or updated RDF-resource might match multiple HTTP-documents, leading to several key questions:
- Should the RDF-resource be exposed in all matching HTTP-documents, only some, or just one?
- What should be done if no HTTP-document matches?
- What happens if a resource is updated? Can it be modified at all? Should it be relocated? Does the description change? Many more of these questions can be asked, and to address them,
we introduce the Storage Guidance Vocabulary (SGV) and accompanying Storage Guiding Framework (SGF) [9]. SGV allows the structure of a Solid pod to be described, while SGF uses this description to guide clients in managing RDF-resources within Solid pods. Using SGF, clients can interpret the Solid pod as a collection of RDF-data, instead of a collection of HTTP-documents containing RDF-data.
Storage Guiding Framework
The Storage Guidance Vocabulary, used by SGF, provides a structured way to describe the relationships between RDF resources in a Solid pod and the LDP mechanisms that expose them via HTTP documents. This section provides a high level overview of the vocabulary and its use, details are omitted for brevity but can be found in previous work [9].
SGV adopts a collection-based approach, where resources are organized into one or more resource collections. We define the following types of collections:
- Resource Collection: A group of related RDF resources.
- Unstructured Collection: A traditional LDP container or HTTP document.
- Canonical Collection: A structured resource collection containing specific resources.
Canonical Collections are further described by the following properties:
- Resource Description: A method to describe resources, such as ShEx [10] or SHACL [11].
- Group Strategy: Describes how resources are grouped (e.g., posts grouped by creation date).
- Store Condition: Describes which collection(s) store a resource when multiple collections are eligible, creating a priority system.
- Update Condition: Specifies behaviour when a resource within a collection is modified.
- Client Control: Defines the extent to which a client can deviate from the SGV description.
Using SGF, RDF resources can be created in a Solid pod through the following process:
- Client fetches the SGV description of the target pod.
- Client checks all canonical collections, filtering out those whose resource description does not match the to-be-created resource.
- Client determines which canonical collections will store the resource based on storage conditions.
- For each selected collection, the client applies the grouping strategy to compute the appropriate HTTP document to store the RDF-resource.
- Client performs the necessary HTTP requests.
A similar process is used for updating and removing RDF resources:
- Client fetches the SGV description of the target pod.
- Client virtually applies the update by computing the triple difference, and fetching required HTTP documents.
- For each modified RDF resource, the corresponding update condition is evaluated, which might result in: a) a prohibition of the modification, or b) an indication that the resource should be relocated to a new collection.
- Client performs the necessary HTTP requests.
SGF has been implemented within a SPARQL [12, 13] query engine that wraps around the Comunica SPARQL query engine [14]. This engine enables data consumers to both query and update Solid pod data while interpreting the pod as a collection of RDF data rather than a set of HTTP documents containing RDF-data. This eliminates the access path data-dependency previously faced.
Demonstration
The demonstration showcases how the SGF query engine enables querying and updating data in a Solid pod. The demo pods are derived from those used in SolidBench [8] and have been enriched with SGV descriptions. As such, the pods follow the same data model as SolidBench, where each pod contains posts and comments from the pod owner. The posts and comments are exposed through four different fragmentation strategies, namely: 1. grouped by creation date, 2. grouped by location, 3. each post and comment has its own HTTP-document, and 4. all posts and comments are grouped together.
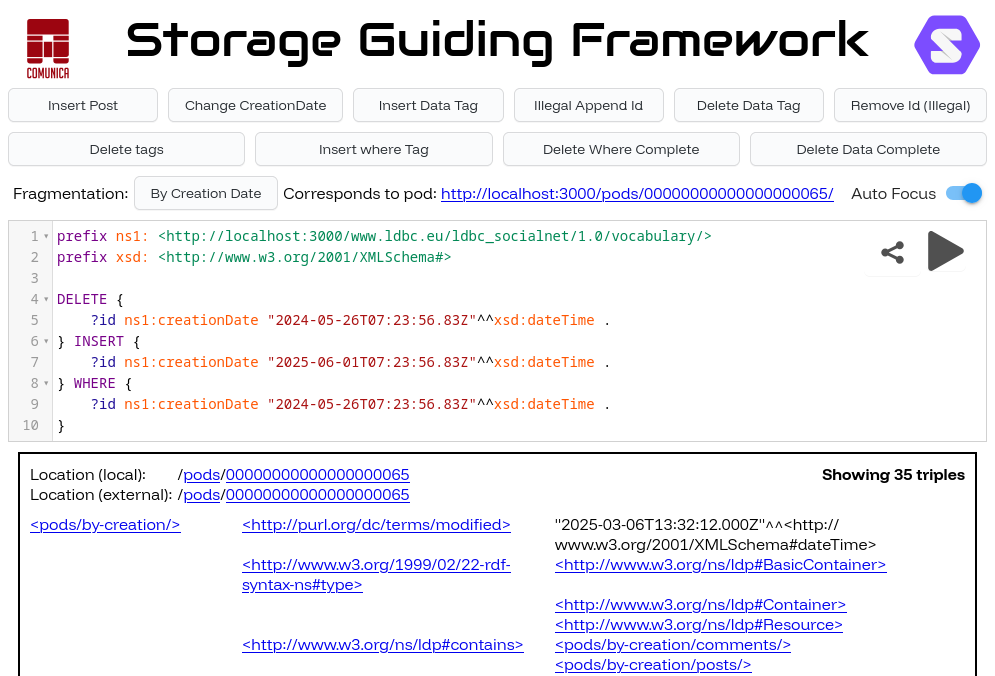
Fig. 1: UI of demo. Source Code + Docker, Video.
Users can load prepared queries into the query editor by selecting them via buttons at the top of the web-interface or write their own queries.
Executing the query in the query editor will perform the required updates in the pod selected using the fragmentation selector.
A simple triple browser has been implemented allowing you to browse the different pods using the web interface.
After executing a query, the triple browser will automatically reload the focussed HTTP-document and highlight added triples.
When the Auto Focus switch is enabled, the triple browser will automatically focus an HTTP-document that was modified by running the query.
Additionally, a direct link to the focused HTTP resource is provided for easy navigation to the pod’s web interface.
Conclusion
In this work, we introduced a framework that enables smart clients to autonomously determine the appropriate HTTP document(s) for storing newly created or updated data on an LDP interface. Our work includes mechanisms to verify whether a resource can be created or deleted. We validated the expressiveness of our descriptive vocabulary, SGV, by implementing an SGF SPARQL engine. Essentially, SGV provides structure to an otherwise unstructured document store based on LDP, by defining a server-side description of the structure that clients should follow. However, since SGV adopts a collection-based approach, instead of a data-centric approach, the application is limited to collection based interfaces, and future research should focus on data descriptions that relieve the data access path dependency in a more general way.
Acknowledgements. This research was supported by SolidLab Vlaanderen (Flemish Government, EWI and RRF project VV023/10).
Jitse De Smet is a predoctoral fellow of the Research Foundation – Flanders (FWO) (1SB8525N).
Ruben Taelman is a postdoctoral fellow of the Research Foundation – Flanders (FWO) (1202124N).